Latest News
DeepSpeed trained the world’s most powerful language models (MT-530B, BLOOM); learn how.
- [2023/03] Scaling Large-Scale Generative Mixture-of-Expert Multimodal Model With VL-MoE
- [2023/02] Automatic Tensor Parallelism: Enables tensor parallelism by default without an injection policy
- [2022/12] DeepSpeed Data Efficiency: A composable library that makes better use of data, increases training efficiency, and improves model quality
- [2022/11] Stable Diffusion Image Generation under 1 second w. DeepSpeed MII
- [2022/10] DeepSpeed-MII: instant speedup on 24,000+ open-source DL models with up to 40x cheaper inference
- [2022/09] ZeRO-Inference: Democratizing massive model inference
- [2022/07] Azure and DeepSpeed empower easy-to-use and high-performance model training
Extreme Speed and Scale for DL Training and Inference
DeepSpeed is an easy-to-use deep learning optimization software suite that enables unprecedented scale and speed for Deep Learning Training and Inference. With DeepSpeed you can:
- Train/Inference dense or sparse models with billions or trillions of parameters
- Achieve excellent system throughput and efficiently scale to thousands of GPUs
- Train/Inference on resource constrained GPU systems
- Achieve unprecedented low latency and high thoughput for inference
- Achieve extreme compression for an unparalleled inference latency and model size reduction with low costs
DeepSpeed has three innovation pillars:
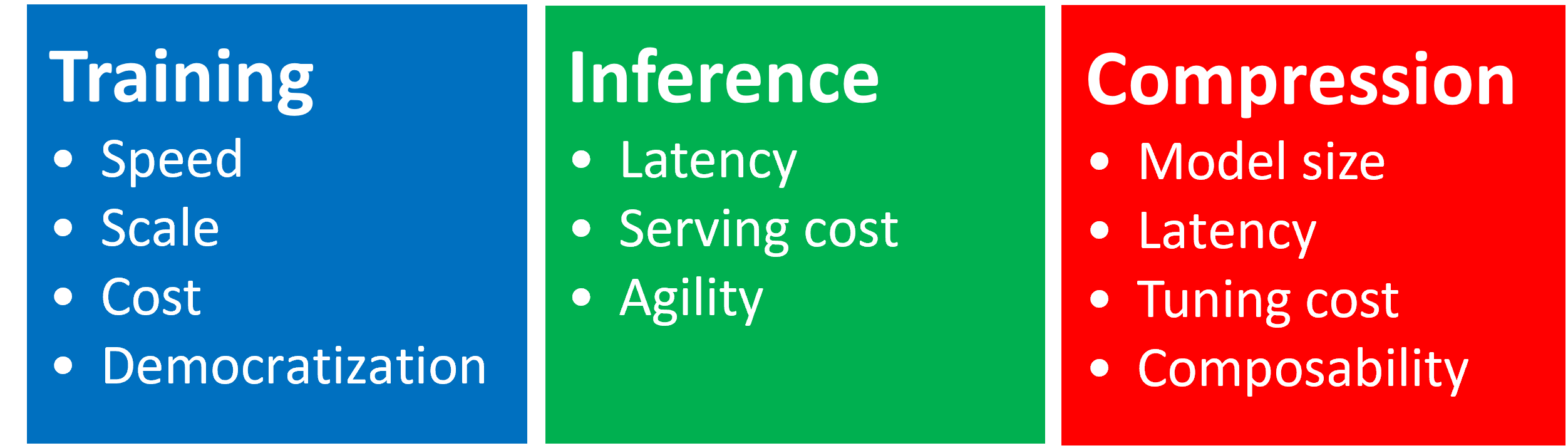
DeepSpeed-Training
DeepSpeed offers a confluence of system innovations, that has made large scale DL training effective, and efficient, greatly improved ease of use, and redefined the DL training landscape in terms of scale that is possible. These innovations such as ZeRO, 3D-Parallelism, DeepSpeed-MoE, ZeRO-Infinity, etc fall under the DeepSpeed-Training pillar. Learn more: DeepSpeed-Training
DeepSpeed-Inference
DeepSpeed brings together innovations in parallelism technology such as tensor, pipeline, expert and ZeRO-parallelism, and combines them with high performance custom inference kernels, communication optimizations and heterogeneous memory technologies to enable inference at an unprecedented scale, while achieving unparalleled latency, thoughput and cost reduction. This systematic composition of system technologies for inference falls under the DeepSpeed-Inference. Learn more: DeepSpeed-Inference
DeepSpeed-Compression
To further increase the inference efficiency, DeepSpeed offers easy-to-use and flexible-to-compose compression techniques for researchers and practitioners to compress their models while delivering faster speed, smaller model size, and significantly reduced compression cost. Moreover, SoTA innovations on compression like ZeroQuant and XTC are included under the DeepSpeed-Compression pillar. Learn more: DeepSpeed-Compression
DeepSpeed Software Suite
DeepSpeed Library
The DeepSpeed library implements and packages the innovations and technologies in DeepSpeed Training, Inference and Compression Pillars into a single easy-to-use, open-sourced repository. It allows for easy composition of multitude of features within a single training, infernece or compression pipeline. The DeepSpeed Library is heavily adopted by the DL community, and has been used to enable some of the most powerful models (see DeepSpeed Adoption).
Model Implementations for Inference (MII)
Model Implementations for Inference (MII) is an open-sourced repository for making low-latency and high-throughput inference accessible to all data scientists by alleviating the need to apply complex system optimization techniques themselves. Out-of-box, MII offers support for thousands of widely used DL models, optimized using DeepSpeed-Inference, that can be deployed with a few lines of code, while achieving significant latency reduction compared to their vanilla open-sourced versions.
DeepSpeed on Azure
DeepSpeed users are diverse and have access to different environments. We recommend to try DeepSpeed on Azure as it is the simplest and easiest method. The recommended method to try DeepSpeed on Azure is through AzureML recipes. The job submission and data preparation scripts have been made available here. For more details on how to use DeepSpeed on Azure, please follow the Azure tutorial.
DeepSpeed Adoption
DeepSpeed has been used to train many different large-scale models, below is a list of several examples that we are aware of (if you’d like to include your model please submit a PR):
- Megatron-Turing NLG (530B)
- Jurassic-1 (178B)
- BLOOM (176B)
- GLM (130B)
- YaLM (100B)
- GPT-NeoX (20B)
- AlexaTM (20B)
- Turing NLG (17B
- METRO-LM (5.4B)
DeepSpeed has been integrated with several different popular open-source DL frameworks such as:
| Documentation | |
|---|---|
| Transformers with DeepSpeed | |
 |
Accelerate with DeepSpeed |
 |
Lightning with DeepSpeed |
 |
MosaicML with DeepSpeed |
DeepSpeed is an integral part of Microsoft’s AI at Scale initiative to enable next-generation AI capabilities at scale.
Contributing
DeepSpeed welcomes your contributions! Please see our contributing guide for more details on formatting, testing, etc.
Contributor License Agreement
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
Code of Conduct
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
Publications
- Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He. (2019) ZeRO: memory optimizations toward training trillion parameter models. arXiv:1910.02054 and In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC ‘20).
- Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. (2020) DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ‘20, Tutorial).
- Minjia Zhang, Yuxiong He. (2020) Accelerating Training of Transformer-Based Language Models with Progressive Layer Dropping. arXiv:2010.13369 and NeurIPS 2020.
- Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, Yuxiong He. (2021) ZeRO-Offload: Democratizing Billion-Scale Model Training. arXiv:2101.06840 and USENIX ATC 2021.
- Hanlin Tang, Shaoduo Gan, Ammar Ahmad Awan, Samyam Rajbhandari, Conglong Li, Xiangru Lian, Ji Liu, Ce Zhang, Yuxiong He. (2021) 1-bit Adam: Communication Efficient Large-Scale Training with Adam’s Convergence Speed. arXiv:2102.02888 and ICML 2021.
- Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, Yuxiong He. (2021) ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning. arXiv:2104.07857 and SC 2021.
- Conglong Li, Ammar Ahmad Awan, Hanlin Tang, Samyam Rajbhandari, Yuxiong He. (2021) 1-bit LAMB: Communication Efficient Large-Scale Large-Batch Training with LAMB’s Convergence Speed. arXiv:2104.06069 and HiPC 2022.
- Conglong Li, Minjia Zhang, Yuxiong He. (2021) The Stability-Efficiency Dilemma: Investigating Sequence Length Warmup for Training GPT Models. arXiv:2108.06084 and NeurIPS 2022.
- Yucheng Lu, Conglong Li, Minjia Zhang, Christopher De Sa, Yuxiong He. (2022) Maximizing Communication Efficiency for Large-scale Training via 0/1 Adam. arXiv:2202.06009.
- Samyam Rajbhandari, Conglong Li, Zhewei Yao, Minjia Zhang, Reza Yazdani Aminabadi, Ammar Ahmad Awan, Jeff Rasley, Yuxiong He. (2022) DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale arXiv:2201.05596 and ICML 2022.
- Shaden Smith, Mostofa Patwary, Brandon Norick, Patrick LeGresley, Samyam Rajbhandari, Jared Casper, Zhun Liu, Shrimai Prabhumoye, George Zerveas, Vijay Korthikanti, Elton Zhang, Rewon Child, Reza Yazdani Aminabadi, Julie Bernauer, Xia Song, Mohammad Shoeybi, Yuxiong He, Michael Houston, Saurabh Tiwary, Bryan Catanzaro. (2022) Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model arXiv:2201.11990.
- Xiaoxia Wu, Zhewei Yao, Minjia Zhang, Conglong Li, Yuxiong He. (2022) Extreme Compression for Pre-trained Transformers Made Simple and Efficient. arXiv:2206.01859 and NeurIPS 2022.
- Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xiaoxia Wu, Conglong Li, Yuxiong He. (2022) ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers. arXiv:2206.01861 and NeurIPS 2022.
- Reza Yazdani Aminabadi, Samyam Rajbhandari, Minjia Zhang, Ammar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Jeff Rasley, Shaden Smith, Olatunji Ruwase, Yuxiong He. (2022) DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale. arXiv:2207.00032 and SC 2022.
- Zhewei Yao, Xiaoxia Wu, Conglong Li, Connor Holmes, Minjia Zhang, Cheng Li, Yuxiong He. (2022) Random-LTD: Random and Layerwise Token Dropping Brings Efficient Training for Large-scale Transformers. arXiv:2211.11586.
- Conglong Li, Zhewei Yao, Xiaoxia Wu, Minjia Zhang, Yuxiong He. (2022) DeepSpeed Data Efficiency: Improving Deep Learning Model Quality and Training Efficiency via Efficient Data Sampling and Routing. arXiv:2212.03597.
- Xiaoxia Wu, Cheng Li, Reza Yazdani Aminabadi, Zhewei Yao, Yuxiong He. (2023) Understanding INT4 Quantization for Transformer Models: Latency Speedup, Composability, and Failure Cases. arXiv:2301.12017.
- Syed Zawad, Cheng Li, Zhewei Yao, Elton Zheng, Yuxiong He, Feng Yan. (2023) DySR: Adaptive Super-Resolution via Algorithm and System Co-design. ICLR:2023.
- Sheng Shen, Zhewei Yao, Chunyuan Li, Trevor Darrell, Kurt Keutzer, Yuxiong He. (2023) Scaling Vision-Language Models with Sparse Mixture of Experts. arXiv:2303.07226.
- Quentin Anthony, Ammar Ahmad Awan, Jeff Rasley, Yuxiong He, Aamir Shafi, Mustafa Abduljabbar, Hari Subramoni, Dhabaleswar Panda. (2023) MCR-DL: Mix-and-Match Communication Runtime for Deep Learning arXiv:2303.08374 and will appear at IPDPS 2023.
Videos
- DeepSpeed KDD 2020 Tutorial
- Overview
- ZeRO + large model training
- 17B T-NLG demo
- Fastest BERT training + RScan tuning
- DeepSpeed hands on deep dive: part 1, part 2, part 3
- FAQ
- Microsoft Research Webinar
- Registration is free and all videos are available on-demand.
- ZeRO & Fastest BERT: Increasing the scale and speed of deep learning training in DeepSpeed.
- DeepSpeed on AzureML
- Community Tutorials